











AIデータセンター向け最新液冷技術 セミナー配布資料 一式
【収録内容:計8本の大ボリュームパッケージ】
- 最新液冷技術・市場動向レポート (全6本 A4約100ページ)
- 解説用プレゼンテーション資料 (全2本)
AIデータセンターの運用において最大のボトルネックとなる「冷却問題」を突破する最新の液冷技術。これからのインフラ戦略に欠かせない高解像度なノウハウと予測を網羅した、実務直結の資料セットです。
提供価格:2万2,000円
制作・提供:今泉 大輔(株式会社インフラコモンズ 代表)
※リンク先の「さっつーのAIエージェント」サイトよりご購入いただけます。
ソフトバンクが国産AIサーバーを開発することが発表されました。NVIDIAやFoxconn(鴻海精密工業)と協業することが報じられています。
Seizo Trend: ソフトバンクが国産AIサーバー製造へ、米NVIDIAや台湾のFoxconnと協議 – 国内完結型の「ソブリンAI」戦略を加速 – (2026/5/12)
さて、どのようにすればソフトバンクが国産AIサーバーを製造販売できるのでしょうか?それを理解するカギになるのが、既存の主要AIサーバー = GPUサーバー各社の事業展開がどうなっているか?を理解することです。
以下のレポートは2025年3月中旬に作成したものですが、GPUサーバーの中身のAI半導体は今でもNVIDIA Blackwell系。全く古くなっていませんので、このレポートをお読みになって、ソフトバンクが計画していることを推察してみてはいかがでしょうか?50本近い英文資料を取りまとめています。
本レポートは、日本のAIデータセンター事業者およびインフラ設計者を対象とし、NVIDIAのHopper世代(H100/H200)からBlackwell世代(GB200/GB300等)への移行に伴う技術的変革と、それに伴うインフラ設計のパラダイムシフトを詳述するものである。
AIモデルの巨大化に伴い、計算資源の単位は単体サーバーからラックスケール、さらにはデータセンター全体を一つの計算機と見なす「AI Factory」へと進化している。Blackwell世代、特にGB300 NVL72は、1ラックあたり120kWを超える電力密度と完全液体冷却(DLC)を要求し、従来の空冷設計では対応不可能な領域に達している。
本レポートでは、GPUサーバーの市場動向、ラックスケール・アーキテクチャ、ネットワーク・インターコネクトの最新仕様を解説するとともに、NVIDIA、Supermicro、Dell、HPEの4社が展開する独自の垂直統合およびエンタープライズ統合戦略を深掘りし、次世代AIインフラ実装のための指針を提示する。
1. 市場動向とアーキテクチャの進化:HopperからBlackwellへ
1.1. GPUサーバー市場の急成長とNVIDIAの独占的地位
現在のGPUサーバー市場は、生成AIの爆発的な普及を背景に、歴史的な成長局面にある。世界市場規模は2024年の1,280億ドルから、2034年には1兆5,600億ドルに達すると予測されており、年平均成長率(CAGR)は28.2%に及ぶ 1。この市場においてNVIDIAは、ディスクリートGPU市場の約92%という圧倒的なシェアを握っており、AIアクセラレータ市場においても80%以上の支配力を維持している 2。
この独占的な地位を支えているのは、単なるチップの演算性能ではなく、CUDAを中心としたソフトウェアエコシステムと、迅速なアーキテクチャの更新サイクルである。NVIDIAは1年単位のイノベーション・ケイデンスを確立しており、H100(Hopper)のリリースからわずか2年足らずでBlackwell世代へと移行し、さらにその改良版であるBlackwell Ultra(GB300)を投入している 3。
1.2. Hopper世代の成果とBlackwellへの技術的飛躍
Hopper世代(H100/H200)は、第1世代のTransformer Engineと高帯域メモリ(HBM3/HBM3e)の導入により、AIトレーニングの効率を劇的に向上させた。特にH200は141GBのHBM3eを搭載し、推論性能においても高い評価を得た。しかし、数兆パラメータ規模のモデル学習やリアルタイム推論においては、単一ノード内でのメモリ帯域とGPU間通信がボトルネックとなっていた。
Blackwellアーキテクチャは、これらの課題を「ラックスケール・コンピューティング」という概念で解決しようとしている。Blackwellは、第2世代のTransformer EngineによりFP4精度の演算をサポートし、推論スループットをHopper世代比で最大30倍向上させる 5。さらに、Blackwell Ultra(GB300)では、1GPUあたりのHBM3e容量が288GB、メモリ帯域が8TB/sにまで拡張され、超大規模モデルをメモリ内に保持することが可能となった 4。
| 仕様項目 | Hopper (H100) | Blackwell (B200) | Blackwell Ultra (B300) |
| アーキテクチャ | Hopper | Blackwell | Blackwell Ultra |
| 製造プロセス | TSMC 4N (Custom) | TSMC 4NP (Custom) | TSMC 4NP (Custom) |
| GPUメモリ容量 | 80GB HBM3 | 192GB HBM3e | 288GB HBM3e |
| メモリ帯域幅 | 3.35 TB/s | 8 TB/s | 8 TB/s |
| FP4 AI性能 | 非対応 | 10 PetaFLOPS | 15 PetaFLOPS |
| 最大電力 (TGP) | 700W | 1,200W | 1,400W |
4
2. Blackwellプラットフォームの構造:GB200/GB300 NVL72
2.1. ラックを一つのGPUとして定義するNVL72アーキテクチャ
Blackwell世代の主力製品であるGB200およびGB300 NVL72は、36基のGrace CPUと72基のBlackwell GPUを単一のラックに統合した、完全液冷式のプラットフォームである 5。第5世代のNVLink Switch Systemにより、ラック内の全72基のGPUが広帯域・低遅延で相互接続され、全体で「1.4エクサフロップスの演算性能を持つ巨大な単一GPU」として機能する 4。
このアーキテクチャの核心は、130TB/sに達するNVLink帯域幅にある。これにより、混合精度(Mixed-precision)トレーニングや、Mixture-of-Experts(MoE)モデルにおける頻繁なオールツーオール通信を、ネットワークアダプタを介さずにラック内で完結させることができる 9。
2.2. コンピュート・トレイとスイッチ・トレイの詳細構成
DGX GB200/GB300ラックの内部構造は、高度にモジュール化されている。
- コンピュート・トレイ: 1Uサイズのトレイに2基のGrace CPUと4基のBlackwell GPUを搭載する 10。Grace CPUは72個のArm Neoverse V2コアを持ち、GPUとはNVLink-C2Cで接続されている。この構成により、CPUメモリ(LPDDR5X)とGPUメモリ(HBM3e)がコヒーレントに統合され、大規模データの処理を効率化している 6。
- NVLinkスイッチ・トレイ: 各ラックに9基のスイッチ・トレイが搭載され、合計18基のNVSwitchを構成する 11。各スイッチは72個のNVLinkポートを持ち、200Gbps(SerDes)のシグナリングレートで動作する 10。
- 物理インターコネクト: ラック背面には1,728本の銅製Twinaxケーブル(長さ最大2m)が張り巡らされており、光トランシーバの消費電力を排除しつつ、極低遅延なインターコネクトを実現している 10。
2.3. Blackwell Ultra (GB300) の戦略的意義
GB300 NVL72は、推論性能とエネルギー効率をさらに極めたモデルである。GB200と比較してAI性能が1.5倍向上している一方で、電力効率(TPS/MW)は5倍改善されている 6。これは、推論タスクにおける「テストタイム・スケーリング(推論時の計算量拡大)」や「エージェント型AI」の要求に応えるための進化であり、数兆パラメータ規模のマルチモーダルモデルにおけるリアルタイム応答を実現する 6。
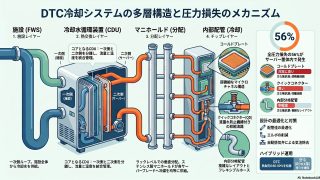
3. インフラ要件:電力デリバリーと液体冷却(DLC)
3.1. 120kW超のラック電力密度と受電トポロジー
Blackwell世代の導入において、データセンター事業者が直面する最大の障壁は、ラックあたりの消費電力の急増である。GB200/GB300 NVL72ラックの消費電力は約120kWから140kWに達し、従来の空冷設計(通常20kW以下)を完全に置き去りにしている 10。
電力供給の効率を最大化するため、ラック内には50V-51Vのバスバー構造が採用されている。AC/DC変換は電源シェルフ内で行われ、94.5%の効率を達成している 10。
- 電圧設計: 415V/50-60Hzの入力系統を用いることで、線電流を168Aに抑え、銅線の断面積を削減(70mm²)する設計が推奨されている。これに対し、208V系統では335Aもの電流が流れ、4/0 AWGという極太のケーブルが必要となり、実装難易度が高まる 10。
- 電力品質: 高調波歪み(THD)を5%未満に抑え、0.97以上の力率を維持するための高精度な電力アナライザの設置が不可欠である 10。
3.2. 液体冷却(Direct-to-Chip)の強制化
チップの熱密度が空気による熱交換能力を超えたため、Blackwell世代では液体冷却(DLC)が事実上の標準となっている 14。水は空気と比較して熱輸送能力が3,300倍高く、この物理的特性の違いが冷却システムの設計を決定づけている 14。
| 冷却パラメータ | 仕様・要件 |
| 冷却方式 | 直接チップ冷却 (DLC / DTC) + リアドア熱交換器 (RDHx) |
| 推奨冷却液 | 脱イオン水 + 30% プロピレングリコール |
| 供給水温 (Secondary Loop) | 15°C ~ 18°C (ジャンクション温度 83-87°C 維持のため) |
| 最小流量 | 30 L/min |
| 圧力損失 | ループ全体で約 2.1 bar |
| 漏水対策 | QDC (Quick Disconnect) 継手、導電性センサー (感度 0.1 mL) |
10
液体冷却の導入により、サーバーファンの消費電力が削減され、データセンター全体の電力使用効率(PUE)を1.03から1.1の範囲にまで低減できる。これは空冷システムの標準的なPUE(1.5-1.8)と比較して、30%以上の二酸化炭素排出量削減に寄与する 15。
3.3. 日本国内での実装における建築的制約
日本国内の既存データセンターでBlackwellを導入する場合、以下の物理的制約が顕在化する。
- 床荷重: 液体を充填したラックとCDU(冷却水循環装置)の総重量は、1ラックあたり1.5トンから2トンを超える場合があり、既存のフリーアクセルフロアの耐荷重(通常500kg-1,000kg/m²)を上回る可能性がある 12。
- 天井高: ラックの高さが50Uに達するケース(Dell IR7000等)もあり、配管スペースを含めた有効天井高の確保が必要である 19。
4. AIクラスタのネットワーク構造とインターコネクト
4.1. 三層ネットワーク・スケーリング
次世代AIクラスタは、3つのスケーリング層で構成される 20。
- Scale-Up (ラック内): 前述のNVLinkにより、全GPUを単一のコヒーレントな計算資源として統合する。
- Scale-Out (ラック間): 数百から数千のラックをInfiniBandまたはEthernetで接続し、大規模なトレーニングクラスタを構築する。
- Scale-Across (拠点間): 地理的に分散したデータセンターを統合し、AIスーパーファクトリー化する技術(Spectrum-XGS) 20。
4.2. InfiniBand vs Spectrum-X Ethernet
大規模クラスタのバックエンドネットワークにおいては、NVIDIAのQuantum-X800 InfiniBandとSpectrum-X800 Ethernetの二つの選択肢がある 22。
InfiniBandは、ハードウェアベースのフロー制御(Credit-Based)により「ゼロ・パケットロス」を実現し、2μs未満の極低遅延を提供する 24。SHARP v4技術により、ネットワークスイッチ自体が演算(リダクション操作等)を行うことで、GPUの計算負荷をオフロードする 25。これは数万基規模のLLM学習において、計算効率の線形スケーラビリティを確保するための必須技術である 22。
対してSpectrum-X800 Ethernetは、標準的なEthernetエコシステムとの親和性を維持しつつ、RoCE v2をAI向けに最適化している 21。適応型ルーティング(Adaptive Routing)と輻輳制御アルゴリズムにより、従来のEthernetで課題であったパケットのジッタと遅延を抑制し、クラウドネイティブなAI環境や推論クラスタにおいて高いコストパフォーマンスを発揮する 21。
4.3. BlueField-3 DPUとConnectX-8 SuperNIC
各GPUコンピュート・トレイには、800Gbpsの帯域を持つConnectX-8 SuperNICが搭載され、Quantum-X800またはSpectrum-X800へのゲートウェイとなる 6。また、BlueField-3 DPUがネットワーク処理やストレージアクセス、セキュリティ管理をCPUからオフロードすることで、計算資源の100%をAIタスクに割り当てることを可能にしている 6。
5. 主要ベンダー4社の戦略分析
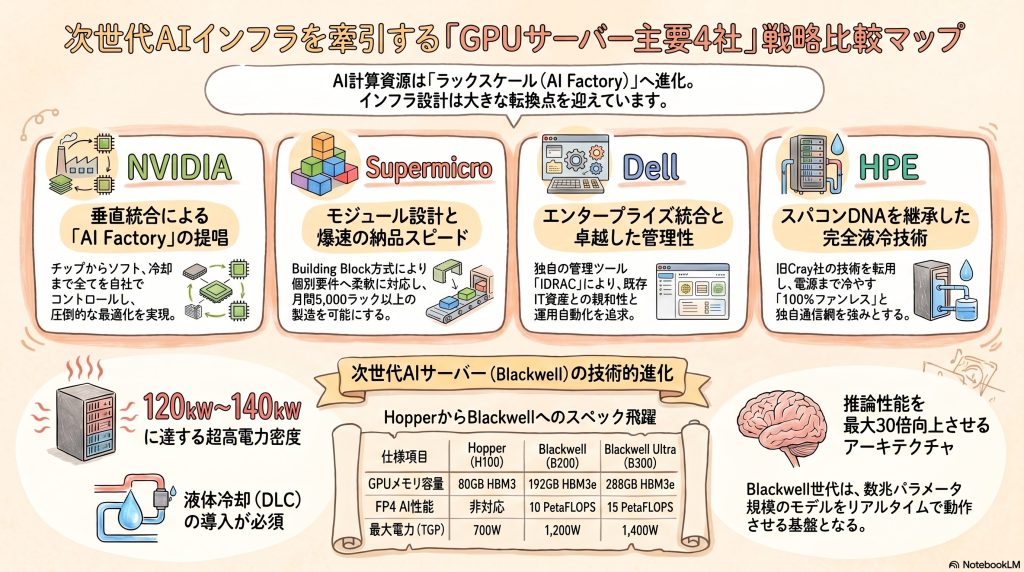
5.1. NVIDIA:垂直統合によるAI Factoryの提唱
NVIDIAの戦略は、半導体メーカーから「AI Factory全体を設計するインフラ企業」への転換である 27。同社は自らラック設計を行い、MGXリファレンスアーキテクチャを通じて、パートナー企業が迅速に認定システムを構築できるよう支援している 4。
- DGX Cloud: 自社のハードウェアスタックをクラウドサービスとして提供し、OracleやAzureと連携することで、エンタープライズ顧客へのリーチを拡大している 30。
- 垂直統合: チップ、ネットワーク、冷却、ソフトウェア(CUDA/DOCA/NIM)の全てを自社でコントロールすることで、他社には真似できない最適化レベルを実現している 6。
5.2. Supermicro:柔軟なBuilding Blockと驚異的な納品スピード
Supermicroは「Building Block Solutions」というモジュール設計を武器に、顧客の個別要件に合わせた迅速なカスタマイズを提供している 7。
- 製造能力: 米国、台湾、オランダの拠点で月間5,000ラック以上の製造キャパシティを持ち、大規模なAI Factoryの短期間での構築に対応できる 29。
- 冷却の多様性: 250kWクラスのインラックCDUから、施設水を使用しない「Liquid-to-Air」サイドカーCDUまで、顧客の施設環境に合わせた柔軟な液冷オプションを用意している 12。
- L11/L12検証: サーバー単体ではなく、ラック単位(L11)およびクラスタ単位(L12)での厳格なバーンインテストを出荷前に行うことで、現場での立ち上げ時間を最小化している 29。
バーンインテスト(Burn-in test)は、電子部品(特に半導体)の出荷前に、高温・高電圧の負荷をかけて初期故障を意図的に発生させ、不良品を取り除くスクリーニング検査。製品の信頼性を高め、市場での故障(初期不良)を防ぐ「エージング」の役割を果たす。
5.3. Dell Technologies:エンタープライズ統合とAI Data Platform
Dellは、既存のIT資産を持つ企業がAIを導入する際の「信頼性と管理性」を強調している。
- iDRACと管理エコシステム: Dell独自の管理ツールであるiDRACは、GPUの監視指標を4倍提供し、システムデプロイを最大9倍高速化、ミスカンフィグレーションの検出を3倍迅速化する 37。
- IR7000ラック: 50Uの大型設計を採用し、Blackwell世代のみならず将来のさらに高電力なプロセッサにも対応可能なモジュール式プラットフォームを提供している 19。
- 垂直統合データプラットフォーム: PowerScaleストレージと、Dataloopの技術をベースとした「Data Orchestration Engine」を組み合わせ、データの準備、学習、推論までを一気通貫でサポートする 40。
5.4. HPE:スーパーコンピューティングのDNAと完全液冷
HPEは、買収したCrayの技術をベースに、ハイエンドなスーパーコンピューティング(HPC)とAIの融合を主導している。
- 100%ファンレス液冷: HPE Cray EXアーキテクチャを転用し、チップだけでなく、メモリ、スイッチ、電源ユニットに至るまで液体で冷却する「100%ファンレス」システムを標榜している 43。
- HPE Slingshot: InfiniBandに対抗する独自の高性能インターコネクトを提供し、数千ノード規模での高スケーラビリティを実証している 46。
- GreenLakeを通じた従量課金: 自社保有が難しい最新のBlackwell環境を、オンプレミスのGreenLakeサービスとして提供し、企業の財務的な柔軟性をサポートしている 48。
6. 実装における技術的詳細と運用のベストプラクティス
6.1. 電気設備設計の再定義
Blackwellラックを導入するには、受電設備(特高変電所)からラックまでの低圧配電経路を根本から見直す必要がある。
- 力率改善: 0.97という高い力率を実現しているが、大量のラックが並ぶ場合、高調波フィルタの設置が必須である 10。
- 冗長性 (N+N): 電源シェルフはN+Nの冗長構成をとるが、受電系統(A系統・B系統)の完全な分離と、各系統の最大負荷容量の確保が求められる 4。
6.2. 液体冷却システムの保守・運用
液体冷却への移行は、IT運用部門とファシリティ運用部門の密接な連携を強いる。
- 水質管理: 二次系ループの導電率は10 µS/cm以下に保つ必要があり、定期的な水質分析(Conductivity, pH, TOC)が欠かせない。これを怠ると、マイクロチャネルの腐食や目詰まりが発生し、GPUのサーマルスロットリングや故障を招く 10。
- フィルター交換: 5µmのプリーツフィルターを1,000時間毎、最終段の1µmフィルターを2,000時間毎に交換するスケジュール管理が必要である 10。
- 漏水検知と自動遮断: 0.1mL単位の微細な漏水を検知した場合、即座に該当ラックの電力供給を停止し、CDUのポンプを制御するロジックを実装すべきである 10。
6.3. ソフトウェア・オーケストレーション
Blackwellクラスタの運用には、NVIDIA Mission ControlやDOCA、さらにはベンダー独自の管理ツール(HPE Supercomputing Management SoftwareやDell iDRAC)を統合した管理レイヤーが必要となる 6。
- マルチテナント管理: リソースの物理的な分離が難しいNVLinkドメインにおいて、仮想化技術(vSphere 9.0等)やMIG(Multi-Instance GPU)を用いて、計算資源を効率的かつ安全に分配する 5。
- エネルギー監視: ラック単位でのリアルタイムな電力消費と冷却効率(PUE)を可視化し、ワークロードのスケジューリングに反映させることで、ESG目標の達成を支援する 10。
7. 結論
NVIDIA HopperからBlackwell世代への移行は、コンピューティングの歴史における重大な転換点である。単なる性能向上にとどまらず、120kWという極限の電力密度と液体冷却の強制化は、データセンターの物理設計、受電トポロジー、そして運用保守のあり方を根底から覆している。
日本のデータセンター事業者は、既存の空冷設備に固執することなく、液体冷却への早期投資と、床荷重や電力供給経路といった建築的制約の解消に注力すべきである。ベンダー選択においては、迅速な拡張を重視するならSupermicro、エンタープライズ統合と管理性を重視するならDell、そして究極の冷却効率とHPC的なスケーラビリティを求めるならHPEというように、自社の戦略に合致したパートナーを選定することが肝要である。
Blackwell世代、特にBlackwell Ultra(GB300)がもたらす推論性能の飛躍は、AIが単なる「学習の対象」から、実世界で自律的に動作する「エージェント」へと進化するための基盤となる。この巨大な技術の波を、インフラの側面からいかに支え、実装できるかが、今後のデジタル競争力を決定づける要因となるだろう。
引用文献
- AI Server Market Size & Share, Statistics Report 2025-2034 – Global Market Insights, 3月 18, 2026にアクセス、 https://www.gminsights.com/industry-analysis/ai-server-market
- NVIDIA Controls 92% of the GPU Market in 2025 and Reveals Next Gen AI Supercomputer, 3月 18, 2026にアクセス、 https://carboncredits.com/nvidia-controls-92-of-the-gpu-market-in-2025-and-reveals-next-gen-ai-supercomputer/
- Data Center GPU Market Size, Share, Industry Report, 2025 To 2030 – MarketsandMarkets, 3月 18, 2026にアクセス、 https://www.marketsandmarkets.com/Market-Reports/data-center-gpu-market-18997435.html
- NVIDIA Blackwell GB200 GB300 Server Details and GB300 Ultra AI Chip Specs Revealed, 3月 18, 2026にアクセス、 https://www.technetbooks.com/2025/08/nvidia-blackwell-gb200-gb300-server.html
- GB200 NVL72 | NVIDIA, 3月 18, 2026にアクセス、 https://www.nvidia.com/en-us/data-center/gb200-nvl72/
- Designed for AI Reasoning Performance & Efficiency | NVIDIA GB300 NVL72, 3月 18, 2026にアクセス、 https://www.nvidia.com/en-us/data-center/gb300-nvl72/
- Supermicro Expands Its NVIDIA Blackwell System Portfolio with New Direct Liquid-Cooled (DLC-2) Systems, Enhanced Air-Cooled Models, and Front I/O Options to Power AI Factories, 3月 18, 2026にアクセス、 https://www.supermicro.com/en/pressreleases/supermicro-expands-its-nvidia-blackwell-system-portfolio-new-direct-liquid-cooled-dlc
- Comparing NVIDIA Blackwell Configurations – AMAX Engineering, 3月 18, 2026にアクセス、 https://www.amax.com/comparing-nvidia-blackwell-configurations/
- NVIDIA GB300 NVL72: A leap in AI performance and efficiency | genai-research, 3月 18, 2026にアクセス、 https://wandb.ai/onlineinference/genai-research/reports/NVIDIA-GB300-NVL72-A-leap-in-AI-performance-and-efficiency–VmlldzoxMzQ2MjcwNg
- NVIDIA GB300 NVL72: Blackwell Ultra Deployment | Introl Blog, 3月 18, 2026にアクセス、 https://introl.com/blog/why-nvidia-gb300-nvl72-blackwell-ultra-matters
- Hardware — NVIDIA DGX GB Rack Scale Systems User Guide, 3月 18, 2026にアクセス、 https://docs.nvidia.com/dgx/dgxgb200-user-guide/hardware.html
- Supermicro NVIDIA GB200 NVL72 Datasheet, 3月 18, 2026にアクセス、 https://www.supermicro.com/datasheet/datasheet_SuperCluster_GB200_NVL72.pdf
- Why liquid cooling will dominate AI data centres in 2026 | Lombard Odier, 3月 18, 2026にアクセス、 https://www.lombardodier.com/insights/2026/january/ai-supercharges-the-race.html
- Liquid Cooling vs Air Cooling for AI Data Centers: 2025 Analysis – Introl, 3月 18, 2026にアクセス、 https://introl.com/blog/liquid-vs-air-cooling-ai-data-centers
- Air-Cooled vs Liquid-Cooled AI Servers for H200 Deployment | Performance, Cost & Scale Guide – Uvation, 3月 18, 2026にアクセス、 https://uvation.com/articles/air-cooled-vs-liquid-cooled-ai-servers-how-to-future-proof-your-h200-server-deployment
- Liquid Cooling vs Air Cooling: Which Is Better for Your System? – Pre Rack IT, 3月 18, 2026にアクセス、 https://prerackit.com/liquid-cooling-vs-air-cooling-which-is-better-for-your-system/
- On-Prem AI Infrastructure: Comparing Dell, HPE, & More | IntuitionLabs, 3月 18, 2026にアクセス、 https://intuitionlabs.ai/articles/on-prem-ai-infrastructure-comparison
- Lenovo NVIDIA GB300 NVL72 Rack Scale AI Product Guide, 3月 18, 2026にアクセス、 https://lenovopress.lenovo.com/lp2357-lenovo-nvidia-gb300-nvl72-rack-scale-ai
- Dell IR7000 rack: NVIDIA GB200 NVL4, 480kW liquid cooling, heat-capture design, 3月 18, 2026にアクセス、 https://www.youtube.com/watch?v=mx9o2NwRIGU
- NVIDIA Spectrum-XGS Ethernet Builds Giga-Scale AI Super Factory – NADDOD Blog, 3月 18, 2026にアクセス、 https://www.naddod.com/blog/nvidia-spectrum-xgs-ethernet-builds-giga-scale-ai-super-factory
- From scale/scaling to scale: Spectrum-XGS is the inevitable choice – Exhibition – FOCC Fiber, 3月 18, 2026にアクセス、 https://www.focc-fiber.com/info/from-scale-scaling-to-scale-spectrum-xgs-is-t-103147995.html
- InfiniBand vs. Ethernet: Choosing the Right Network Fabric for AI Clusters – Arc Compute, 3月 18, 2026にアクセス、 https://www.arccompute.io/arc-blog/infiniband-vs-ethernet-choosing-the-right-network-fabric-for-ai-clusters
- RoCE vs InfiniBand: Networking for NVIDIA GPUs in AI Infrastructure – Global-Scale, 3月 18, 2026にアクセス、 https://global-scale.io/roce-vs-infiniband-ai-infrastructure/
- InfiniBand vs Ethernet: Broadcom and NVIDIA Scale-Out Tech War | TrendForce, 3月 18, 2026にアクセス、 https://www.trendforce.com/insights/infiniband-vs-ethernet
- InfiniBand Switches: NVIDIA Quantum-X800 and the XDR Generation Powering AI Supercomputers – Introl, 3月 18, 2026にアクセス、 https://introl.com/blog/infiniband-switches-quantum-x800-xdr-sharp-ai-supercomputer-2025
- NVIDIA Quantum-X800 InfiniBand Platform, 3月 18, 2026にアクセス、 https://www.nvidia.com/en-us/networking/products/infiniband/quantum-x800/
- NVIDIA Vera Rubin Opens Agentic AI Frontier – NVIDIA Investor Relations, 3月 18, 2026にアクセス、 https://investor.nvidia.com/news/press-release-details/2026/NVIDIA-Vera-Rubin-Opens-Agentic-AI-Frontier/default.aspx
- HPE simplifies and accelerates development of AI-ready data centers with secure AI factories powered by NVIDIA | HPE, 3月 18, 2026にアクセス、 https://www.hpe.com/us/en/newsroom/press-release/2025/12/hpe-and-nvidia-simplify-ai-ready-data-centers-with-secure-next-gen-ai-factories.html
- Build AI Factories with Supermicro and NVIDIA, 3月 18, 2026にアクセス、 https://www.supermicro.com/en/accelerators/nvidia/ai-factory
- NVIDIA GB300 NVL72: Next-generation AI infrastructure at scale | Microsoft Azure Blog, 3月 18, 2026にアクセス、 https://azure.microsoft.com/en-us/blog/microsoft-azure-delivers-the-first-large-scale-cluster-with-nvidia-gb300-nvl72-for-openai-workloads/
- Oracle Cloud Infrastructure Deploys Thousands of NVIDIA Blackwell GPUs for Agentic AI and Reasoning Models, 3月 18, 2026にアクセス、 https://blogs.nvidia.com/blog/oracle-cloud-infrastructure-blackwell-gpus-agentic-ai-reasoning-models/
- Generative AI SuperCluster | Supermicro, 3月 18, 2026にアクセス、 https://www.supermicro.com/en/solutions/ai-supercluster
- Supermicro Reveals DCBBS® with New NVIDIA Vera Rubin NVL72, HGX Rubin NVL8, and Vera CPU Systems, Designed to Accelerate Customer Time-to-Market, 3月 18, 2026にアクセス、 https://www.bastillepost.com/global/article/5694869-supermicro-reveals-dcbbs-with-new-nvidia-vera-rubin-nvl72-hgx-rubin-nvl8-and-vera-cpu-systems-designed-to-accelerate-customer-time-to-market
- Supermicro Showcases the Future of HPC Clusters and AI Infrastructure at Supercomputing 2025, 3月 18, 2026にアクセス、 https://www.supermicro.com/en/pressreleases/supermicro-showcases-future-hpc-clusters-and-ai-infrastructure-supercomputing-2025
- rack scale solutions – Supermicro, 3月 18, 2026にアクセス、 https://www.supermicro.com/manuals/brochure/Brochure-Rack-Services.pdf
- Rack Scale Solutions – Supermicro, 3月 18, 2026にアクセス、 https://www.supermicro.com/en/solutions/rack-integration
- Dell vs Supermicro Servers: Comparison Guide for Data Center – Varidata, 3月 18, 2026にアクセス、 https://www.varidata.com/knowledge-en/dell-vs-supermicro-servers-comparison-guide-for-data-center/
- Why Dell Server Management Tools Outperform HPE: Comparative Analysis, 3月 18, 2026にアクセス、 https://www.dell.com/en-us/blog/why-dell-server-management-tools-outperform-hpe-comparative-analysis/
- Dell PowerEdge Named 2025 Market and Innovation Leader in Servers for AI, 3月 18, 2026にアクセス、 https://www.dell.com/en-us/blog/dell-poweredge-named-2025-market-and-innovation-leader-in-servers-for-ai/
- Nvidia GTC: Dell upgrades AI Factory to enable ROI – Fierce Network, 3月 18, 2026にアクセス、 https://www.fierce-network.com/cloud/nvidia-gtc-dell-upgrades-ai-factory-push-past-pilot
- Dell AI Factory with NVIDIA Delivers Proven Path to Enterprise AI ROI, 3月 18, 2026にアクセス、 https://www.dell.com/en-us/dt/corporate/newsroom/announcements/detailpage.press-releases~usa~2026~03~dell-ai-factory-with-nvidia-delivers-proven-path-to-enterprise-ai-roi.htm
- Dell expands AI Factory with new data platform, infrastructure and agentic AI features, 3月 18, 2026にアクセス、 https://siliconangle.com/2026/03/16/dell-expands-ai-factory-new-data-platform-infrastructure-agentic-ai-features/
- HPE Cray Supercomputing EX solution for the year 2025, 3月 18, 2026にアクセス、 https://www.hpe.com/psnow/doc/a50011628enw
- Supercomputing products | HPE, 3月 18, 2026にアクセス、 https://www.hpe.com/us/en/supercomputing.html
- Next-generation HPE Cray Supercomputing portfolio introduces industry-leading compute density to boost AI productivity | HPE, 3月 18, 2026にアクセス、 https://www.hpe.com/us/en/newsroom/press-release/2025/11/next-generation-hpe-cray-supercomputing-portfolio-introduces-industry-leading-compute-density-to-boost-ai-productivity.html
- HPE Cray EX – M Computers s.r.o., 3月 18, 2026にアクセス、 https://mcomputers.cz/en/hpe-cray-ex/
- HPE Powers the Next Frontier in AI and Supercomputing with “Discovery” and “Lux” for Oak Ridge National Laboratory – Efficiently Connected, 3月 18, 2026にアクセス、 https://www.efficientlyconnected.com/hpe-powers-the-next-frontier-in-ai-and-supercomputing-with-discovery-and-lux-for-oak-ridge-national-laboratory/
- Dell vs HPE: NVIDIA-Powered AI Platforms Explained – virtualizationvelocity, 3月 18, 2026にアクセス、 https://www.virtualizationvelocity.com/home/choosing-the-right-nvidia-powered-enterprise-ai-platform-dell-and-hpe
- Liquid Cooling For AI Data Centers Market Analysis, Size, and Forecast 2025-2029, 3月 18, 2026にアクセス、 https://www.technavio.com/report/liquid-cooling-for-ai-data-centers-market-industry-analysis
HPE Bolsters Server, Software Lineup for AI and HPC – HPCwire, 3月 18, 2026にアクセス、 https://www.hpcwire.com/2026/03/16/hpe-bolsters-server-software-lineup-for-ai-and-hpc/

